







ChessBase 17 - Megapaket - Edition 2024
ChessBase ist die persönliche Schach-Datenbank, die weltweit zum Standard geworden ist. Und zwar für alle, die Spaß am Schach haben und auch in Zukunft erfolgreich mitspielen wollen. Das gilt für den Weltmeister ebenso wie für den Vereinsspieler oder den Schachfreund von nebenan
Lange Zeit wurden bei der Schachprogrammierung regelbasierte Ansätze verwendet. Diese Programme verwendeten eine Vielzahl von fest codierten Regeln und Heuristiken, um Schachpositionen zu bewerten und die besten Züge auszuwählen.
Der Wendepunkt kam mit dem Erfolg von AlphaZero, einem Schachprogramm, das von DeepMind (einem Tochterunternehmen von Google) entwickelt wurde. AlphaZero startete nur mit den fest codierten Regeln, wie die Figuren auf dem Brett gezogen werden können und wann eine Partie z.B. durch Patt oder Matt beendet ist. Alles weitere hat sich AlphaZero durch Selbstspiel beigebracht. Das bei diesem Training erworbene Wissen wurde in sogenannten neuronalen Netzen gespeichert. Diese Netze wurden dann später in dem Match gegen Stockfish verwendet, um Stellungen zu bewerten. Vereinfacht ausgedrückt sind die neuronalen Netze dafür verantwortlich, den besten Zug in einer Stellung auszuwählen.
Das Ergebnis des Matches AlphaZero gegen Stockfish hat damals klar den Vorteil der neuronalen Netzte gegenüber den fest codierten Regeln gezeigt. Daher haben in der Zwischenzeit alle Engine Entwickler (auch die Stockfish Community) nachgezogen und neuronale Netze in ihren Engines integriert. Wahrscheinlich hat jeder Leser schon gegen eine Engine gespielt, die ein solches Netz verwendet. Abgesehen von der verbesserten Spielstärke der Engine merkt man das in der Regel aber nicht.
Aber was sind eigentlich neuronale Netze? Wie funktionieren sie, wie trainiert man sie und wie setzt man sie in Chess Engines ein? Ich habe mich mit diesen Fragen beschäftigt und werde in diesem Artikel versuchen, Antworten auf diese Fragen zu geben. Dazu werde ich die Grundprinzipien zunächst anhand eines “minimalen” neuronalen Netzes erläutern. Im zweiten Teil werde ich dann zeigen, wie die entsprechenden Prinzipien auf die Schachprogrammierung übertragen werden können. Als Beispiel dafür habe ich das Endspiel König und Turm gegen König ausgewählt. Das klingt im ersten Augenblick einfach. Aber die Herausforderungen liegen im Detail. Wer das nicht glaubt, kann ja mal versuchen, die entsprechenden Regeln (ohne Verwendung von Table Bases) zu programmieren.
Fritz 19 & Fritz Powerbook 2024
Angreifer, Feigling, Schwindler oder Endspiel-Zauberer: Ich zeig’ Dir, wie man gegen jeden Typ gewinnt.
Wenn man einen Artikel über ein so komplexes Thema wie neuronale Netze schreibt, besteht die Gefahr, dass es schnell sehr technisch wird und man sich in Details verliert. Daher habe ich folgenden Ansatz gewählt.
In dem Artikel werde ich mein Vorgehen in einer Art beschreiben, so dass es (hoffentlich) möglich ist, ohne tiefe technische Kenntnisse zu folgen. Die verwendeten technischen Begriffe werden im Glossar am Ende des Artikels erläutert.
Für diejenigen, die an den technischen Aspekten der Programmierung interessiert sind, werde ich Links zum Programmcode bereitstellen. Dieses erfolgt in Form von Colab Notebooks. Diese Notebooks kann man sich als virtuelle Computer vorstellen, die man in seinem Lieblingsbrowser bedienen kann. Folgt man den angegeben Links, kann man über “Laufzeit -> alles ausführen auswählen” den Code selber ausführen. Bei Interesse kann man Parameter ändern und schauen, was passiert. Man muss keine Hemmungen haben. Es kann nichts kaputt gehen und es ist kostenlos.
Schauen wir uns nun zunächst an, wie neuronale Netze aufgebaut sind. Ein solches Netzwerk besteht zunächst aus Knoten, die als Neuronen bezeichnet werden. In der Regel werden diese Neuronen in Ebenen gegliedert. Jedes Netz hat mindestens eine Input- und eine Output-Ebene. In der Regel liegen zwischen Input und Output noch beliebig viele versteckte Ebenen.
Neuronen einer Ebene sind mit Neuronen der nächsten Ebene verbunden. Es gibt verschiedene Ansätze wie diese Verbindungen organisiert werden. Wir gehen aber hier davon aus, dass jedes Neuron einer Ebene mit allen Neuronen der nächsten Ebene verbunden ist.
Den Verbindungen werden Gewichte zugeordnet, die beeinflussen, wie stark ein Neuron das entsprechende Neuron der nächsten Ebene beeinflusst. Gewichte sind in unserem minimalen Netz Faktoren, mit dem der Wert des Ausgangsknoten multipliziert wird, bevor der Wert an den Zielknoten übergeben wird. Im Zielknoten werden dann alle Eingangswerte akkumuliert.
Ein einfaches Beispiel für ein solches neuronales Netzwerk würde aus einer Input-Ebene mit zwei Neuronen und einer Output-Ebene mit einem Neuron bestehen. Versteckte Ebenen werden in diesem Beispiel nicht verwendet.
Das Einsatzgebiet für dieses Netzwerk könnte z.B. ein Experiment aus dem Physikunterricht sein, wo wir zwei Eingabevariablen (X1 und X2) selber einstellen und dann einen Ausgabewert (Y) messen. Die Daten können wie folgt aussehen:
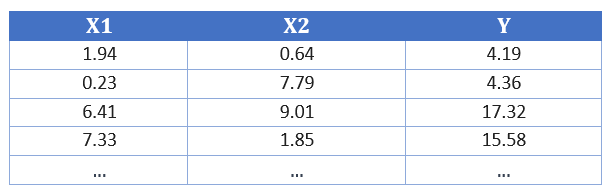
Abbildung 1: Messwerte
Die Aufgabe wäre nun vorauszusagen, welchen Wert Y hat, wenn wir z.B. X1=10 und X2=20 setzen. Wie müsste ein neuronales Netz aussehen, mit dem wir die Vorhersage hinbekommen? Dazu legen wir ein neues Colab Notebook an, das über diesen Link erreicht werden.
Der Anfang ist einfach. Wir haben die beiden Input-Neuronen X1 und X2 sowie den Output-Neuron Y. Versteckte Zwischeneben benötigen wir nicht, daher verbinden wir sowohl X1 als auch X2 mit Y.
Das Netz würde aktuell wie folgt aussehen:
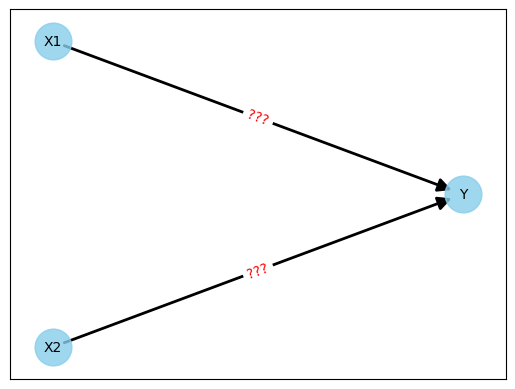
Abbildung 2: Initiales neuronales Netzwerk ohne Gewichte
Jetzt kommt der schwierige Part. Was machen wir mit den Gewichten (in der Abbildung als “???” dargestellt)? Wie müssen diese Gewichte gewählt werden, damit wir Y-Werte möglichst genau vorhersagen können?
Bei neuronalen Netzen löst man dieses mit Training. Dazu werden die Messwerte aus Abbildung 1 verwendet, um das Netz anzulernen.
Bei dem Training startet man mit initialen Gewichten. Dafür gibt es unterschiedliche Strategien. Man kann z.B. alle Gewichte auf null setzen oder Zufallswerte einsetzen. Ich habe mich für die Zufallswerte entschieden und danach folgendes Netz erhalten:
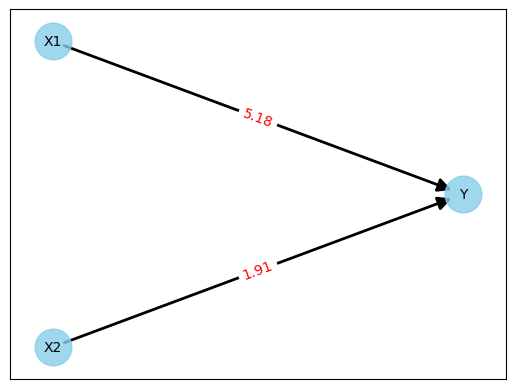
Abbildung 3: Neuronales Netzwerk mit Zufallsgewichten
Machen wir einen kurzen Test mit der ersten Zeile der Messwerte aus Abbildung 1. Demnach wäre
Y = 5.18 * 1.94 + 1.91 * 0.64
Y = 11.06
Das ist nicht gut, da wir als Ergebnis 4.19 erwartet hätten; wir liegen also fast um den Faktor 3 daneben. Aber es hätte noch deutlich schlechter sein können, da wir die Gewichte ja gewürfelt hatten. Und in der Tat ist es vollkommen egal, wie gut oder schlecht das Netz am Anfang ist. Entscheidend ist das Training (oder Anlernen) des Netzes.
Schauen wir uns jetzt das Training genauer an. Der folgende, von mir stark vereinfachte Programmablauf, hat sich in den letzten Jahren als Standard etabliert:
| Für alle vorliegenden Messwerte | (1) |
| outputs = neuronales_netz(X1, X2) | (2) |
| loss = outputs-Y | (3) |
| do_backpropagation () | (4) |
| aktualisiere_gewichte() | (5) |
Abbildung 4: Training eines neuronalen Netzwerks
Kurze Erläuterung zu diesen Codezeilen:
Die Hauptarbeit liegt sicherlich in Schritt 4. Das Gute ist aber, dass man auch als Programmierer dazu wenig Gedanken machen muss, da es entsprechende Frameworks wie z.B. das von mir verwendete PyTorch gibt, die diese Aufgabe übernehmen.
Wiederholt man das ganze einhundert Mal (dauert nur wenige Sekunden), so erhält man folgendes Netz:
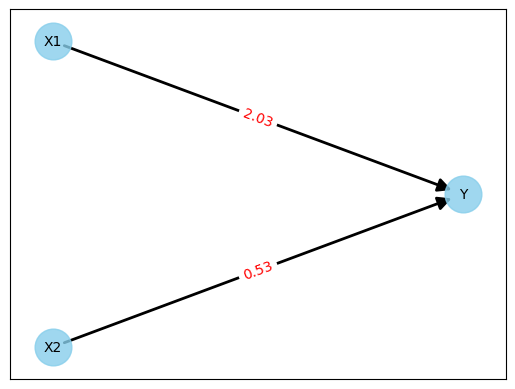
Abbildung 5: Neuronales Netzwerk nach Training
Machen wir wieder den Test mit der ersten Zeile der Messwerte aus Abbildung 1. Demnach wäre
Y = 2.03 * 1.94 + 0.53 * 0.64
Y = 4.2774
Das ist nicht perfekt, da das erwartete Ergebnis 4.19 ist. Aber eine Abweichung von 0.08 (ca. 2%) ist für unser kleines Experiment nahe genug dran.
Hinweis: Die Messwerte aus Abbildung 1 hatte ich mit Zufallswerten für X1 und X2 und der Formel Y = 2.0 * X1 + 0.5 * X2 generiert. Das perfekte Ergebnis wären also Gewichte mit den Werten 2.0 und 0.5 gewesen. Wenn jemand das Colab Notebook verwendet, um die Schritte nachzuvollziehen, dann nicht überrascht sein, wenn andere Werte rauskommen. Das kommt bei Zufallszahlen schonmal vor.
Machen wir uns nun an die Aufgabe, ein neuronales Netz für eine Schach Engine zu erstellen. Die Aufgabe des Netzes soll es sein, eine Schachstellung möglichst gut zu bewerten.
Der Weg von einem minimalen neuronalen Netz zu einem Netz, das die komplette Bandbreite von Schachstellungen bewerten kann, wäre viel zu weit und zu komplex. Daher habe ich für diesen Artikel ein einfaches Beispiel ausgewählt, das Mattsetzen von König und Turm gegen König. Klingt einfach, aber schauen wir uns mal folgende Stellung an:
Abbildung 6: Stellung König und Turm gegen König (Matt in 32 Halbzügen)
In der Startstellung benötigt man bei bestem Spiel 16 Züge (oder 32 Halbzüge) zum Matt. Würde man diese Suchtiefe bei einer Engine mit einem klassischen Suchalgorithmus (z.B. MiniMax) einstellen, dann müsste man auch bei guter Hardware sehr, sehr lange auf den ersten Zug warten.
Stellt man die Suchtiefe geringer ein, muss man eine gute Stellungsbewertung implementieren. Denn würde man nur das Material zählen, würde sich ja nichts ändern, da Weiß auch bei Zufallszügen seinen Mehrturm behält (wenn er ihn nicht einzügig einstellt). Natürlich gibt es dafür etablierte Lösungen, wie z.B. Bonuspunkte bei der Bewertung, wenn der schwarze König nahe dem Brettrand ist, oder der weiße Turm dem König den Weg abschneidet usw. Aber trivial ist das nicht.
Mit dem neuronalen Netz wollte ich einen anderen Ansatz wählen. Anstatt explizit Regeln zu definieren, wollte ich eine einfache Engine mit einer Suchtiefe von maximal 3 Halbzügen und ohne Funktionen zur Stellungsbewertung so trainieren, dass sie auch bei perfektem Spiel von Schwarz die obige Stellung gewinnt.
Die Schritte sind analog zu dem ersten Beispiel, also
Für das Training ist noch der Zwischenschritt “Trainingsdaten bereitstellen” erforderlich.
Schauen wir uns dafür zunächst einmal an, wie man die Stellung in Abbildung 6 in numerische Werte transferieren kann. Dafür gibt es viele Möglichkeiten, ich habe mich für den folgenden Ansatz entschieden, der sich an Bitboards orientiert. Für jede Figurenart gibt es ein eigenes 8x8 großes Feld. Ist der Wert 1, so bedeutet das, dass eine entsprechende Figur auf dem Feld steht.
Die Stellung aus Abbildung 5 würde dann wie folgt dargestellt:
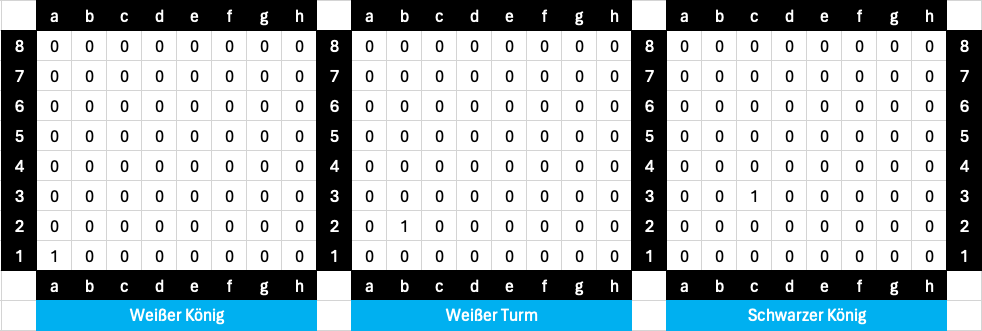
Abbildung 7: Bitboards für die Stellung in Abbildung 5
In Summe hat man dann 3x64 Bitwerte, also insgesamt 192. Ein weiteres Bit spendiert man noch, um kenntlich zu machen, wer am Zug ist (1 = Weiß am Zug, 0 = Schwarz am Zug). So erhält man insgesamt 193 Bitwerte.
Auf den ersten Blick sehen die 193 Eingabewerte für das neuronale Netz sehr verschwenderisch aus, insbesondere da ja nur ein kleines Teilproblem des Schachspiels gelöst werden soll. Schaut man sich aber die aktuelle Netzstruktur von Stockfish an, so stellt man fest, dass dieses, HalfKA genannte Netz über 91.000 Eingabewerte verfügt. Dafür gibt es sicherlich gute Gründe und der Erfolg gibt den Entwicklern ja auch Recht. Aber für unser Beispiel wäre das sicherlich Overkill.
Bei dem Output ist es deutlich einfacher. Erwartet wird ein numerischer Wert, der angibt, wie viele Halbzüge das Matt entfernt ist, also ein Wert zwischen 1 und 32 (längster Weg zum Matt).
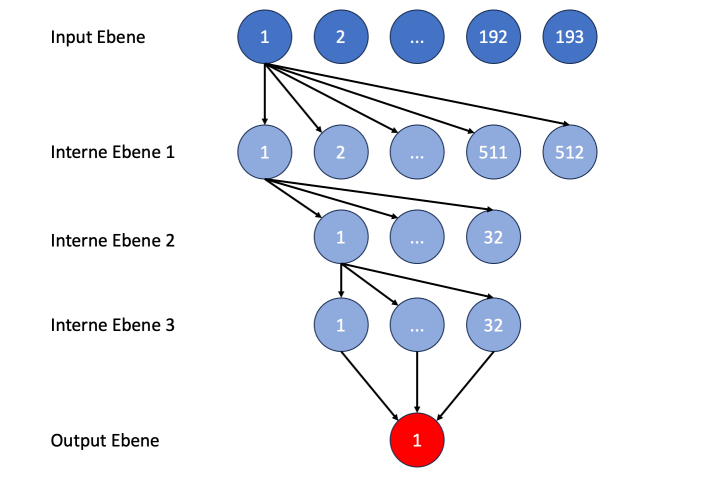
In diesem Netz werden jetzt Zwischenebenen von Knoten benötigt. Stockfish verwendete in der alten, HalfKP genannten Netzstruktur 3 Zwischenebenen mit 512, 32 und 32 Knoten. Es kann nicht verkehrt sein, das zu übernehmen. Unser Netz sieht dann so aus:
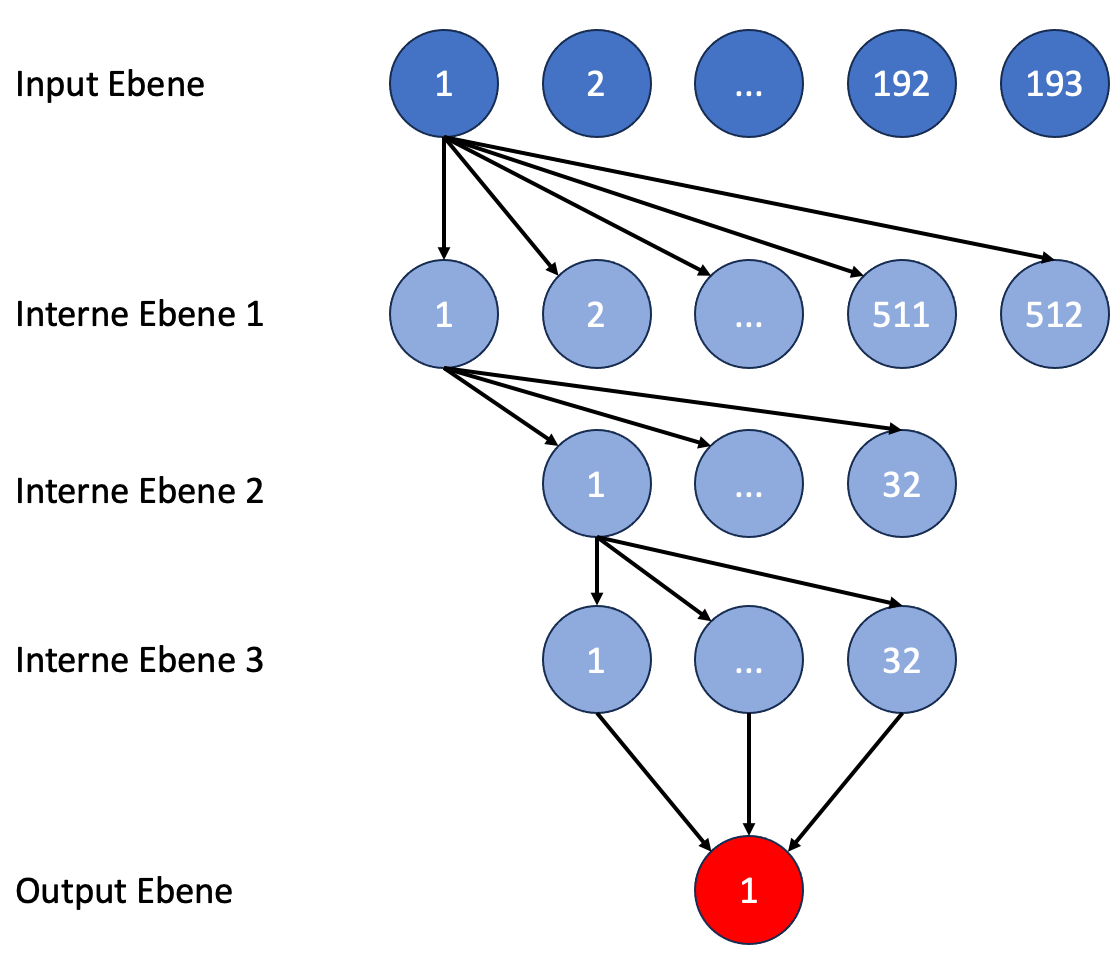
Abbildung 8: Struktur des neuronalen Netzes für Stellungsbewertungen (Nummern geben die Position des Knoten in der jeweiligen Ebene an)
Für diese Aufgabe habe ich ein neues Colab Notebook angelegt, das über diesen Link aufgerufen werden kann. In diesem Notebook habe ich zunächst eine Table Base aus dem Internet heruntergeladen und anschließend mit einem kleinen Programm zufällige Stellungen mit weißem König, weißem Turm und schwarzen König erzeugt. Für dieses Stellungen wurde dann mit Hilfe der Table Base die jeweilige Entfernung zum Matt berechnet. Als Ergebnis habe ich eine Datei bekommen mit folgenden Zeilen:
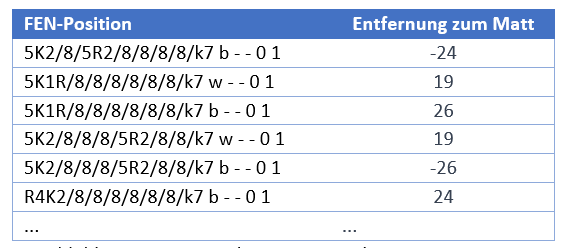
Abbildung 9: Trainingsdaten König und Turm gegen König
Auch hierfür habe ich ein separates Colab Notebook angelegt, das über diesen Link erreichbar ist. Das Training funktioniert nach dem gleichen Schema, das in Abbildung 4 skizziert ist.
Insgesamt habe ich 50 Trainingszyklen (im Fachjargon Epochs genannt) mit den erzeugten Trainingsdaten durchgeführt. In dem referenzierten Colab benötigt der gesamte Trainingslauf weniger als 5 Minuten. Die folgende Abbildung zeigt den Fortschritt beim Training.
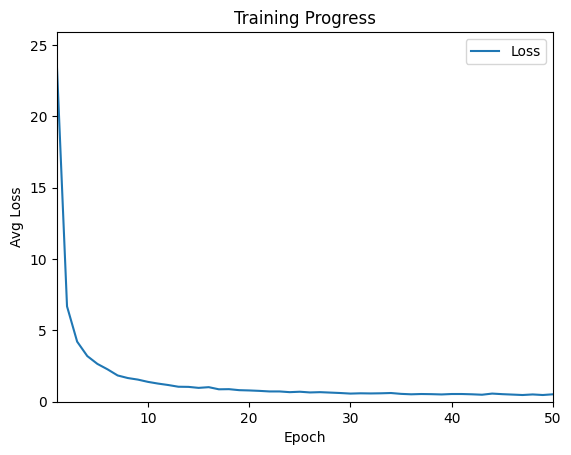
Abbildung 10: Trainingsfortschritt
Man erkennt, dass am Anfang die Fortschritte rasend schnell sind. Der Loss, also der Wert, um den die Bewertung des neuronalen Netzes von dem korrekten Wert abweicht, verringert sich sehr schnell. Ab Epoch 20 ist der Wert unter 1, danach werden die Fortschritte merklich kleiner. Zwischendurch werden die Werte sogar etwas schlechter, verbessern sich dann aber wieder.
Das so trainierte Netz wird am Ende in einer Datei (krk_model.pth) gesichert und kann dann dem finalen Test unterzogen werden.
Finaler Test
Jetzt naht der Augenblick der Wahrheit. Ist das trainierte Netz wirklich in der Lage, Stellungen mit König und Turm gegen König korrekt zu bewerten?
Es gibt nur einen Weg, das rauszubekommen. Ich habe in der Stellung aus Abbildung 6 das neuronale Netz (KRk Model) gegen eine Engine antreten lassen, die mittels Table Base immer den besten Zug auswählt. Das neuronale Netz wurde dazu in die Evaluierungsfunktion einer Engine mit einem MiniMax-Algorithmus eingebaut, der eine Suchtiefe von 3 Halbzügen verwendet. Der Programmcode sieht wie folgt aus:
| def eval (self) | (1) |
| fen = self.new_board.fen() | (2) |
| x = get_krk_bitvector(fen) | (3) |
| eval = self.machine(x) | (4) |
| return eval | (5) |
Abbildung 11: Stellungsevaluierung mit trainiertem neuronalem Netz
In den Zeilen (2) und (3) wird die aktuelle Brettstellung zunächst in die aus Abbildung 7 bekannte Bit-Struktur konvertiert. In Zeile (4) wird dann das neuronale Netz aufgerufen mit der Bit-Struktur als Eingabeparameter. Die Ausgabe ist dann die Entfernung zum Matt, dieser Wert wird dann in Zeile (5) zurückgegeben. Das entsprechende Colab Notebook kann über diesen Link aufgerufen werden.
Die verwendete Engine geht ganz einfach vor. Sie prüft alle legalen Züge in einer Stellung und bewertet diese dann mit Hilfe der Evaluierungsfunktion in Abbildung 11. Der Zug mit der besten Bewertung wird dann ausgewählt.
Lassen wir nun diese Engine gegen eine Table Base Engine spielen:
Im 11. und 12. Zug hat das neuronale Netz geschwächelt. Nur das Wissen, dass eine dreimalige Zugwiederholung drohte, hat die Engine dazu gebracht im 13. Zug Kd6 zu spielen. Ansonsten wäre der Turm weiterhin zwischen e6 und e5 gependelt. Das ist dann auch der Hauptgrund, warum das neuronale Netz statt der optimalen 16 Zügen 4 zusätzliche Züge benötigt hat. Aber das Ergebnis kann sich sehen lassen. Ohne explizite Regeln zu programmieren, hat das neuronale Netz zügig mattgesetzt.
Ich habe danach noch den Selbsttest gemacht und diese Stellung selber gegen die Table Base Engine gespielt. Dabei habe ich 19 Züge zum Mattsetzen gebraucht.
Schlussbemerkungen
Die selbst gestellte Aufgabe, ein neuronales Netz zu erstellen und zu trainieren, dass es ermöglicht, Stellungen mit König und Turm gegen König zu gewinnen, wurde erfüllt. Die dafür eingesetzte Engine kennt nur die Schachregeln (welche Züge sind erlaubt, was ist ein Matt, was ist eine dreifacher Stellungswiederholung usw.). Alles andere übernimmt das neuronale Netz.
Ganz so einfach und geradlinig, wie in diesem Artikel beschrieben verlief die Arbeit nicht. Bei der Definition des Netzes und beim Training des Netzes musste ich experimentieren und es gab den einen oder anderen Rückschlag. Aber wenn ich mal nicht weiterkam, stand ChatGPT mit Rat und Tat zur Seite.
Als nächstes würde ich gerne ein neuronales Netzwerk für das gesamte Spektrum von Stellungen erstellen trainieren. An Trainingsdaten mangelt es nicht. So stellt z.B. Lichess jeden Monat mehr als 90 Millionen Partien zum Download bereit. Ca. 10% dieser Partien wurden von Stockfish analysiert und beinhalten daher für jede Zug in der Partie eine Bewertung. Das Ganze wäre ein deutlich komplexeres und aufwendigeres Unterfangen als das hier im Artikel beschriebene Netz für Stellungen mit König und Turm gegen König. Daher würde ich mich über Mitstreiter freuen. Bei Interesse mich einfach über meine Homepage kontaktieren.
|
Begriff |
Definition |
|
AlphaZero |
AlphaZero ist ein von DeepMind (Tochterunternehmen von Google) entwickeltes Computer Programm. Es ist bekannt für seine Erfolge in Brettspielen wie Schach, Shogi und Go. Das besondere an AlphaZero war, dass nur die Spielregeln implementiert wurde. Alles darüber hinaus hat es sich selbst mittels maschinellen Lernens beigebracht. |
|
Bit Board |
Ein Bit Board ist eine Datenstruktur in der Schachprogrammierung, die dazu verwendet wird, Schachstellungen effizient zu repräsentieren. Statt eine Schachstellung als ein einziges 8x8 Array zu speichern, verwendet Bit Board für jede Figurenart (weißer König, schwarzer König, weiße Dame, ..., schwarzer Bauer) ein eigenes 8x8 Array. In dem 8x8 Array für den weißen König ist der Wert 1 für das Feld, auf dem der König steht und 0 für alle andere Felder. Die 8x8 Arrays für Bauern können bis zu acht Einsen haben. |
|
Colab |
Colab, Kurzform für Colaboratory, ist ein freier Cloudservice von Google, der eine Python Programmierumgebung mit Bibliotheken für das maschinelle Lernen bereitstellt. Colab ist in der AI-Community weitverbreitet, insbesondere bei denjenigen, die keinen Zugriff auf eigene leistungsfähige Hardware haben. |
|
FEN |
Die Forsyth-Edwards-Notation (FEN) ist eine Standartnotation für Schachstellungen. Sie ermöglicht, eine Stellung in einer Textzeile – dem sogenannten FEN-String – zu beschreiben. Die Chessbase Software stellt Funktionen bereit, um zu einer Stellung einen FEN-String zu erzeugen oder umgekehrt, aus einem FEN-String eine Stellung aufzubauen. |
|
MiniMax |
Minimax ist ein Algorithmus, der in der Spieltheorie und in der künstlichen Intelligenz (KI) verwendet wird, um den besten Zug in einem Zwei-Spieler-Spiel zu bestimmen, bei dem jeder Spieler versucht, das beste Ergebnis für sich selbst zu erzielen (Max) und das schlechteste für den Gegner (Min). |
|
Neuronales Netz |
Ein neuronales Netz ist ein Modell, das von der Funktionsweise des menschlichen Gehirns inspiriert wurde. Es besteht aus verbundenen Knoten (Neuronen), die in Schichten organisiert sind. Es wird verwendet, um komplexe Muster und Abhängigkeiten in Daten zu lernen, und findet Anwendung in verschiedenen Aufgaben wie Mustererkennung, Klassifikation, Regression und mehr. |
|
Python |
Python ist eine Programmiersprache, die bekannt ist für die gute Lesbarkeit und die Einfachheit des Codes. Sie wurde von Guido van Rossum entwickelt und zuerst 1991 herausgegeben. Seitdem hat sich Python zu einer der weltweit populärsten Programmiersprachen entwickelt. Python wird in vielen Bereichen eingesetzt wie Webanwendungen, künstliche Intelligenz, maschinelles Lernen und Automatisierung. |
|
Python Chess |
Ist eine populäre Python Bibliothek, die Funktionen für die Speicherung von Schachpositionen und der Generierung von legalen Zügen in einer Stellung bereitstellt. Des weiteren unterstützt sie Standartformate wie z.B. FEN (Forsyth–Edwards Notation). |
|
PyTorch |
PyTorch ist eine Open-Source-Deep-Learning-Bibliothek, die von Facebook AI Research entwickelt wurde. Sie bietet eine flexible Plattform für das Erstellen und Trainieren von neuronalen Netzwerken sowie für andere maschinelle Lernprojekte. Wer sich tiefer mit PyTorch beschäftigen möchte, dem kann ich diesen Kurs der Stanford Universität empfehlen. |
|
Stockfish |
Stockfish ist eine der stärksten Open Source Schachengines. Die Engine wird von Schachspielern und Entwicklern für die Analyse und als Benchmark für andere Schachengines benutzt. |
|
Stockfish NNUE |
Stockfish Efficiently Updated Neural Network Evaluation (NNUE) ist eine Verbesserung der Stockfish Schachengine, die auf der Verwendung von neuronalen Netzen für die Bewertung von Schachstellungen beruht. Eine Darstellung, sowohl der alten HalfKP genannten als auch der neuen HalfKA genannten Netzstrukturen findet man hier. |
|
Table Base |
Table Bases, auch als Endspieldatenbanken bekannt, sind Datenbanken, in denen alle möglichen Stellungen in einem Schachendspiel mit einer kleinen Anzahl von verbleibenden Figuren gespeichert sind. Jeder Stellung ist dabei eine Bewertung in Form der Entfernung zum Matt zugeordnet (falls ein Gewinn bei bestem Gegenspiel möglich ist). |




| Anzeige |










.jpeg)


